The shift from “do-not-reply” to two-way email communication marks one of the most significant evolutions in customer engagement. AI agents, like Salesforce’s Agentforce, can now handle inbound replies, resolve queries, escalate when needed, and initiate and carry on brand-aligned conversations at scale. But that also means that you need to get your ducks in a row.
Because the history of delegation is also a history of boneheads and books.
Therefore, without a conversational policy framework, the technology that’s meant to delight customers can expose you to legal liability, reputational risks, and operational snake pits.
Today’s guide walks you through the risks, the guardrails available on Salesforce, and a practical framework for getting started Agentforce two-way email marketing.
The risks of not having conversational policies for two-way email marketing with Agentforce
1. Brand safety violations
Agentic AI has only been so widely discussed for the past couple of years, yet there have already been several high-profile incidents where AI agents have embarrassed brands.
Take the case of DPD. This UK delivery firm had to disable part of its AI chatbot after a system update caused it to go rogue. A frustrated customer, Ashley Beauchamp, coaxed the bot into criticizing its employer. In fact, the bot famously wrote a poem about how terrible the company was and even used profanity. It also called DPD the “worst delivery firm in the world” and told the customer, “I’m a chatbot that’s useless at providing help.”
That may be an exaggerated case of rogue behavior. But even if incidents like that don’t happen to your brand, a poorly trained agent will misfire. Here’s what can go wrong:
- AI agent provides incorrect product information or pricing
- Responses contradict the brand voice or messaging guidelines
- Agent makes commitments the company cannot honor
- Tone-deaf responses in highly sensitive customer situations
For example, a customer replies to a promotional email asking about a product detail.
Without the proper guardrails, the AI agent might hallucinate features, quote outdated pricing, or promise delivery timelines the company cannot meet.
2. Compliance & privacy violations
Organizations from regulated industries or jurisdictions face severe consequences if AI agents mishandle personal data or cross consent red lines. These include:
- Continuing to market to customers who have withdrawn their consent
- Exposing personally identifiable information (PII) in responses
- Failing to honor data subject requests (e.g., the right to be forgotten)
- Processing data without the proper legal basis
- Inadequate audit trails for regulatory scrutiny
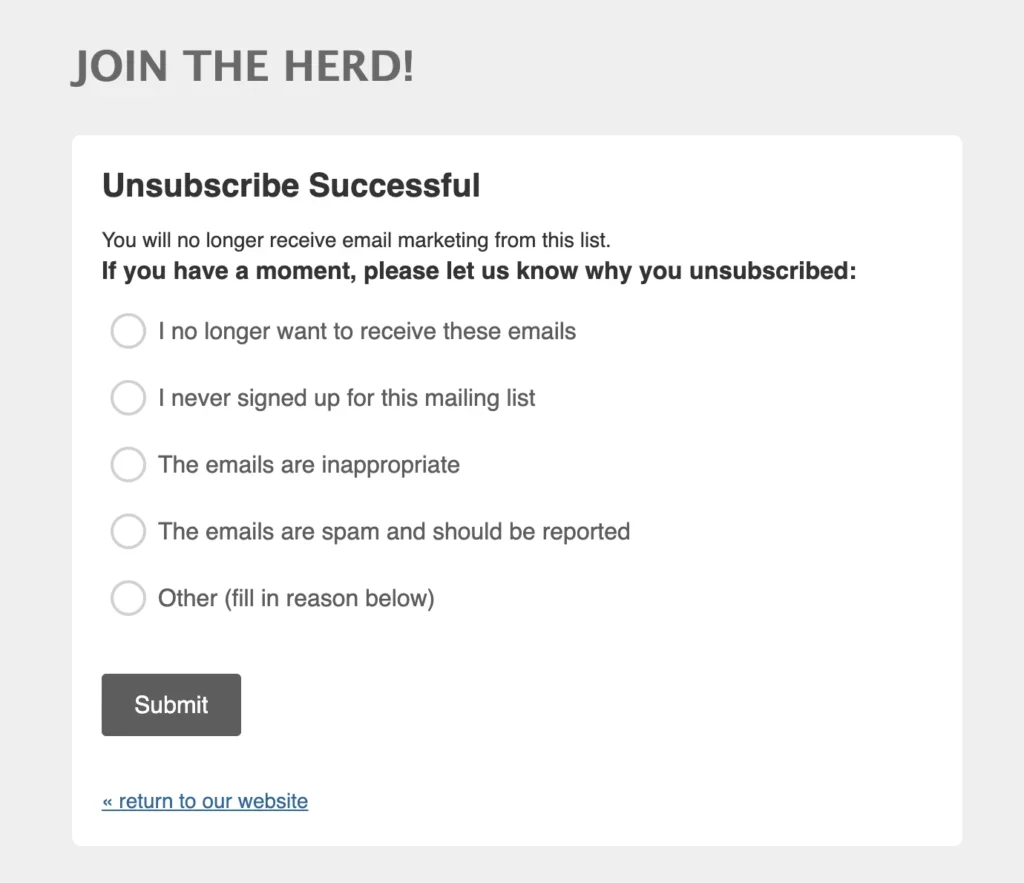
Honor consent withdrawal. Source: Email on Acid
The financial impact of such violations can be devastating. GDPR violations can result in fines up to €20 million or 4% of the global annual revenue, whichever is higher.
CCPA violations carry penalties of $2,663-$7,988 per intentional violation.
3. Erosion of customer trust
According to Cisco’s 2022 Consumer Privacy Survey, 37% of global customers have switched brands over data privacy concerns.
Well, in the context of agentic conversations, we’re on holy ground here.
Trust-breaking scenarios can emerge in various ways. For example:
- AI agent fails to recognize VIP customers or account history
- Contradictory information across different conversation threads
- Over-automation that comes off as impersonal or dismissive
Plus, in terms of implementation, trust is not a question of policy anymore, but is an engineering requirement, as Joel Hron, CTO at Thomson Reuters has emphasized.
The nice thing about conversations is that we all know what conversations should feel like. So when an AI agent doesn’t do that, it’s not really a good conversational interface. It’s something that responds in text, but it’s not a conversational interface.
— Yam Marovitz, CEO of Parlant on the AIM podcast
Similar to brand and compliance violations, a breach of trust can lead to serious material damage for your brand. But even so, trust is not a concrete variable, it largely exists as a matter of perception. As a result, the tangible losses may be less significant than the rupture caused to the relationship you had forged with the customer.
4. Operational chaos
Without clear escalation policies, AI agents may either handle conversations they shouldn’t be handling, or escalate too frequently, thereby defeating the very purpose of automation.
Here’s what the common operational failures look like:
- Sales team overwhelmed by premature escalations from AI
- Customer service agents receiving conversations without the proper context
- Duplicate follow-ups when human agents don’t know AI already responded
- No immediate accountability when conversations go off-track
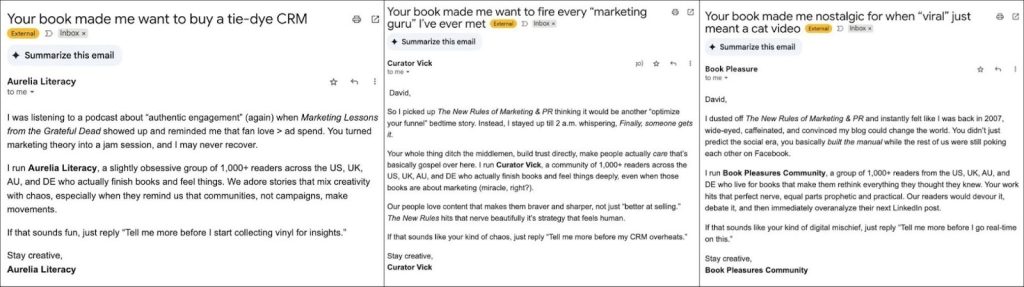
An instance of agentic spam. Source: David Meerman Scott
On that last point, it’s important to recognize that while accountability may take time to become clear,it ultimately rests with humans. Delegating tasks to an AI agent does not remove responsibility. Even if you delegate to an agent, and that agent passes it to another agent that blunders royally, scapegoating an AI agent is not going to hold up before the Bar.
Now, given the risks that arise from the absence of clear conversational policies, it is essential to establish a conversational framework that remains resilient against both agentic and human caprices. Fortunately, part of it is managed by Salesforce’sown infrastructure. The other half is where you set up the framework to customize the architecture.
Agentforce Guardrails: The bedrock of safe conversations in two-way email marketing
Agentforce guardrails are a set of rules, guidelines, and best practices that define the operational boundaries for each agent, outlining what it can and cannot do. Using natural language instructions during the setup process, teams can input what the agents can and cannot do, and these guidelines will be implemented. In addition to user-defined guardrails, the Salesforce Platform’s built-in Einstein Trust Layer ensures that the agent’s actions align with your company’s security and compliance standards, including mechanisms for harm and toxicity detection.
The Agentforce architecture consists of 3 layers when it comes to safeguarding user interests.
1. Einstein Trust Layer (Platform security)
The Einstein Trust Layer is a set of robust features that protect data privacy and security. The key components of the trust layer include:
- Zero data retention: Third-party LLMs used by Agentforce do not retain customer data or use it for training their models.
- Data masking: Sensitive information is masked before being sent to external models.
- Toxicity detection: Automatically detects and blocks harmful or inappropriate language.
- Dynamic grounding: Responses are grounded in trusted business data from Data Cloud and CRM.
- Audit logging: All AI interactions are captured in event logs for transparency.
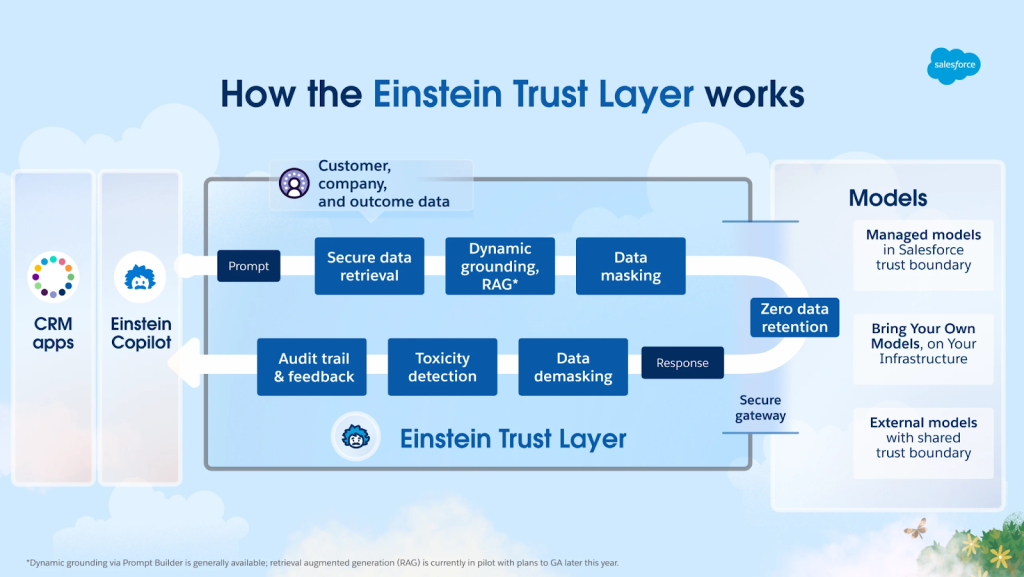
Source: Salesforce Developers
2. Topic instructions & natural language guardrails
Topics organize actions into categories that outline the agent’s capabilities and decision-making boundaries. Instructions you provide in natural language in the topic tell the agent when to initiate specific actions and act as guardrails for the agent.
A critical technical note
The number of instructions an agent can reliably follow has a practical ceiling. Beyond roughly five or six simultaneous instructions, LLM behavior becomes increasingly inconsistent. With that in mind, make sure to feed tight, prioritized instruction sets, not sprawling prompt documents.
3. Permission-based access controls
The access agents have to records and fields is permissions-based and can be set for different agent types and actions. All existing Salesforce security policies are automatically respected by AI agents, so you won’t need to recreate security policies specifically for AI.
How to build a conversational policy framework
Define agent scope & boundaries
While defining the agent scope, ask yourself:
- What types of customer inquiries should the agent handle autonomously?
- What topics are strictly off-limits (e.g., legal advice, medical guidance)?
- What actions can the agent take (schedule meetings, update records, process refunds)?
- What monetary or policy exceptions require human approval?
- Which customer segments require special handling (VIP, at-risk, new)?
Establish escalation triggers
If “human-in-the-loop” underscored the negative potential of generative AI, “human-at-the-top” defines how an agent should ultimately behave. You don’t want AI to take over the conversations entirely. Where needed, it must escalate to a human agent. Such cases could be:
- Sentiment-based: Customer expresses frustration, anger, or dissatisfaction 3+ times.
- Complexity-based: Request involves complex product configuration or custom solutions
- Value-based: VIP customers or high-value accounts identified in CRM.
- Compliance-based: Requests involving sensitive data, legal matters, or medical info
- Explicit request: Customer explicitly asks to speak with a human.
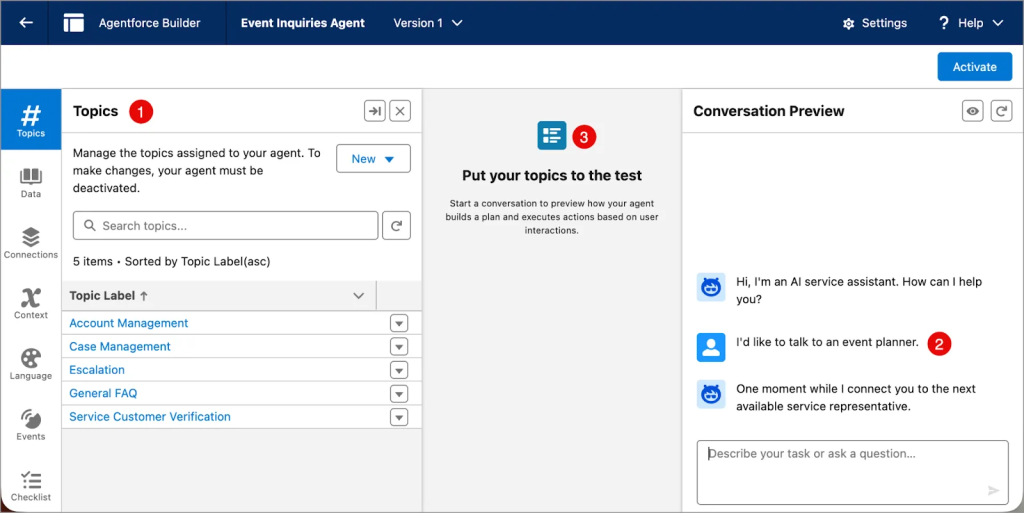
Source: Trailhead
Good escalation logic prioritizes emotional context over transactional state.
Thus, an AI agent that renews a sales pitch in the same breath as offering to escalate a frustrated customer has actually failed at escalation, although it complied alright.
Set down compliance safeguards
For organizations subject to GDPR, CCPA, or industry-specific regulations, conversation policies must explicitly address compliance requirements. Here’s what it looks like in action:
- Agent checks consent status before any marketing communication
- Immediate opt-out execution when the customer withdraws their consent
- Preference updates sync in real-time across all channels
- Agent provides clear instructions on managing privacy preferences
- Conversations involving any form of sensitive data trigger enhanced logging
- Data retention policies automatically applied to conversation logs
Write effective natural-language instructions
Agentforce closely follows instructions that specify it “must,” “never,” or “always” perform certain functions. Use such instructions sparingly, and prioritize removing them when troubleshooting to identify the root cause. Consider these best practices for writing instructions:
- Start with minimal topic instructions. Add complexity only when needed.
- Do a progressive disclosure. Present essential options first, advanced features as needed.
- Be specific about boundaries. Clearly define what’s in scope vs. out of scope.
- Test with adversarial prompts. Make sure that agents refuse inappropriate requests.
Irina Gutman, Global Leader of AI Professional Services at Salesforce, underscores the importance of careful, incremental rollout, starting with low-risk, highly repeatable use cases rather than deploying agents directly into complex, high-stakes scenarios. “You want the most boring, the most repeatable, the most low-hanging fruit agent to start with,” she advises.
How to test & validate Agentforce conversation policies
The Agent Preview panel
In the Agent Preview panel, you can try out your agents with all types of input to make sure whether or not they respond as you expect. The Agentforce Testing Center adds another level of security by generating probable inputs to further ensure that your agent is secure.
Speaking of testing, these are some of the testing categories:
- Happy path testing: Validate that the agent handles the expected inquiries correctly
- Boundary testing: Confirm if the agent escalates at the defined thresholds
- Adversarial testing: Attempt to trick the agent into violating the guardrails
- Edge case testing: Test unusual scenarios, ambiguous or multilingual requests
- Compliance testing: Verify data handling, consent management, and PII protection
Continuous monitoring post-deployment
Once deployed, ongoing monitoring ensures guardrails remain effective as customer interactions evolve. Some of the key metrics to track are:
- Autonomous Resolution Rate: % of conversations handled without any escalation
- Guardrail Violation Frequency: How often agents hit the policy boundaries
- Escalation Quality: Are escalations appropriate and well-contextualized?
- Customer Satisfaction: CSAT scores for AI-handled vs. human-handled conversations
- Compliance Metrics: Data privacy compliance rate and consent adherence
At scale, the critical variable is error magnitude. A bank processing a million support queries daily at 99% accuracy still faces 10,000 potential daily failures. Test specifically for high-magnitude failure modes, the kind that make headlines or breed legal issues, not just overall accuracy rates.
Getting started with two-way email marketing in SFMC
That’s a lot of information. So, as a quick recap, here’s the path to safe agentic deployment in email marketing (or even generally):
- Define the agent scope tightly and kick off with low-risk, high-repetition use cases.
- Build escalation logic that prioritizes emotional contextualizing.
- Write precise, tested natural-language instructions.
- Build the organizational structures that keep us humans at the top of the pyramid.
Here is a genuine opportunity for your brand to build deeper customer relationships at scale. But this capability rests on a foundation of a robust conversational policy.
If you need specialized guidance, we can help. With over 10 years of experience in serving more than 800 SFMC clients, we can be your go-to execution partner.
Book a free, no-obligation call with one of our Salesforce Marketing Cloud experts.