


Agentforce has transformed how marketers will be operating going forward. But with great power comes great responsibility. As Chandrika Shankarnarayan, VP of Product and a Data Cloud expert at Salesforce, says, “The paramount challenge in this agent-driven future is governing this complex data landscape with privacy and security in mind.”
But to be more specific, governance challenges also include the following:
- Agents beginning to act beyond the defined scope (the problem of “super agency”)
- Bias getting embedded across multi-agent systems
- Hallucinations informing autonomous decisions
- Manipulating reward functions to inflate performance metrics
- Limited transparency into reasoning paths
- Difficulty defining the threshold of human intervention
- Uncertainty about how many controls are sufficient
In this scenario, you must be equipped with a new set of governance metrics that provide clear visibility into the overall performance, behavior, and impact of AI agents.
As SFMC experts leveraging agentic AI, we recommend six foundational governance metrics that will undergird Salesforce Agentforce governance best practices.
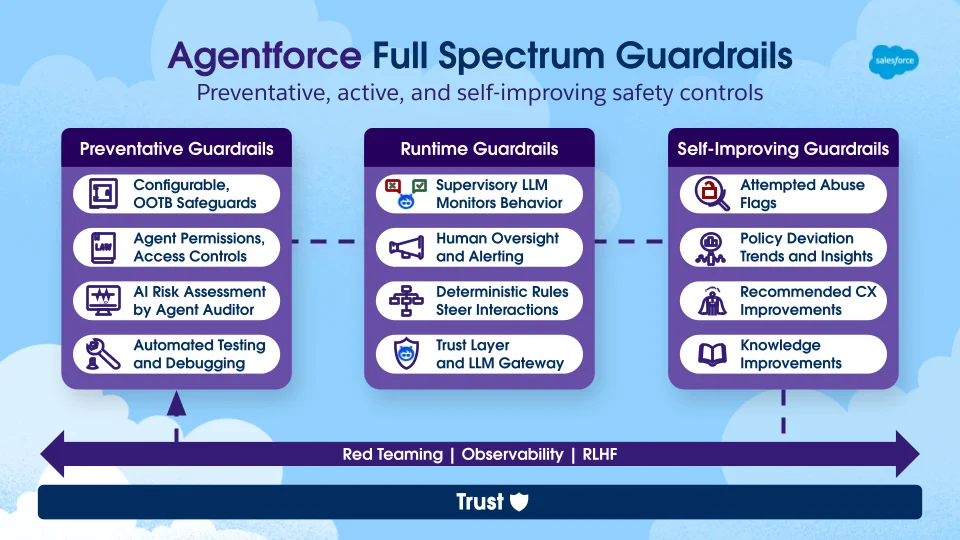
Source: Salesforce
Six Agentforce governance metrics
1. Escalation rate
Definition: Escalation rate is the percentage of AI-handled conversations that require transfer to or intervention by a human agent.
Look at the escalation rate as a calibration signal. Agentforce agents are designed with built-in guardrails that define when a situation exceeds their scope and warrants human involvement. An agent that escalates appropriately is working as intended.
The concern arises at the extremes:
- An extremely low escalation rate can indicate your agent is pushing through conversations it shouldn’t.
- An extremely high rate suggests your agent isn’t trained on the scenarios it encounters, or that your guardrail configuration is too restrictive to be operationally useful.
You’ll need to track this metric over time. A sudden increase in escalations often points to a prompt issue, an underdocumented product launch, or an emerging customer concern your agent wasn’t built to handle.
Bear in mind that escalation should be encoded into the system from the get-go. Accordingly, in your agent’s topic instructions — where you define what the agent can do, should do, and cannot do — you should explicitly specify the conditions under which it pivots to a human.
2. Guardrail violation frequency
Definition: How often agents attempt to cross, or successfully cross, the behavioral, content, or policy boundaries defined in your governance configuration.
Every Agentforce deployment should include explicit guardrails: topics the agent won’t engage with, commitments it won’t make, content it won’t generate, etc. These are defined in natural language during agent setup and enforced through a combination of the Agent Builder configuration and the Einstein Trust Layer, which includes toxicity detection, prompt injection defense, and ethical guardrail enforcement baked directly into the platform.
Now, a high violation frequency usually points to one of these two things:
- Miscalibrated guardrails that are flagging too many legitimate interactions.
- A mismatch between your guardrail definitions and the scenarios your agent.
You’ll need to review violation logs weekly during initial deployment. Then monthly once stable.
Categorize violations by type, and use that data to refine both your configuration and your agent prompts. A downward trend over time, plateauing at a manageable baseline, is the target.
What makes this metric more actionable is Salesforce’s instruction adherence feature. Supervisory LLMs within the Atlas reasoning engine continuously monitor conversations and score them against key dimensions including instruction adherence, factual grounding, and coherence. So if an agent attempts something that violates its instructions, the system can detect the low adherence score and block that response entirely. These logs are available directly in Agent Builder and can be exported for audit and reporting.
3. Conversation completion rate
Definition: The percentage of AI-handled conversations that reached a successful, autonomous resolution without human intervention or conversation abandonment.
It is critical to differentiate a successful completion from an unsuccessful one.
A conversation closed by an agent that gave incorrect information, failed to capture consent, or left a customer confused isn’t a governance win, even if it technically resolved without escalation. Your definition of completion needs to be anchored to quality outcomes, not closure events.
Therefore, you’ll need to measure against criteria that reflect actual resolutions.
A potential driver of low completion rates is over-permissioning. When agents are granted excessive access, they can inherit unintended data or tool access paths that produce confusing, out-of-scope, or erroneous responses. Applying the principle of least privilege directly improves the coherence and reliability of agent outputs.
Declining completion rates are often early indicators of data quality issues, broken integrations, or prompt degradation as your agent encounters new edge cases it wasn’t trained on.
4. Brand safety score
Definition: It measures the frequency, severity, and nature of toxicity detection triggers.
Brand safety represents the highest-visibility risk in any Agentforce deployment.
The reputational asymmetry is severe. Thousands of high-quality agent interactions won’t make the news, but one off-brand or offensive output will. Agentforce addresses this through the Einstein Trust Layer’s toxicity detection capability, which scans both prompts and responses before they’re surfaced to customers. The score should aggregate how often these flags trigger, what categories of content triggered them, and how those triggers trend over time.
But there’s another aspect you need to remember. Beyond the platform-level classifiers, consider whether your industry might require a brand-specific safety layer.
| Industry-specific brand safety layers for Agentforce marketing | |||
|---|---|---|---|
| Industry | Generic filter view | Brand-specific safety layer | Regulatory laws |
| Financial services | Permits general helpfulness | Flags: Unvetted investment advice, “guaranteed” returns, or failure to include “Past performance is not indicative of future results.” | EU AI Act (High-Risk Category); MAS FEAT (Singapore); SEC Rule 2026-A (Cyber & AI operational resiliency). |
| Healthcare / Pharma | Permits medical terminology | Flags: Unofficial diagnoses, treatment recommendations, or discussing off-label uses for proprietary drugs. | HIPAA (Privacy); FDA AI/ML Guidelines; EU AI Act (Annex III) regarding medical devices and triage. |
| Legal / Insurance | Permits explanation of terms | Flags: Language creating an attorney-client relationship or admitting liability/fault in a claim scenario. | GDPR Article 22 (Automated decision rights); Colorado AI Act (Algorithmic discrimination in insurance). |
| High-end luxury | Permits casual assistance | Flags: Use of slang, emojis, or “cheap” descriptors that dilute brand prestige or deviate from the “Elite Concierge” persona. | Fair Housing Act (FHA); California CCPA/ADMT |
| Alcohol & tobacco | Permits lifestyle content | Flags: Language targeting minors, health-benefit claims, or failure to verify age/jurisdiction-specific regulations. | California AI Transparency Act |
| Real estate | Permits property descriptions | Flags: Language that could violate Fair Housing laws (e.g., mentions of neighborhood demographics or “family-friendly” restrictions). | FTC Deceptive Advertising Rules; EU Digital Services Act (DSA) |
| SaaS/Enterprise IT | Permits technical support | Flags: Comparisons to direct competitors’ pricing, unauthorized discounting, or leaking “future roadmap” commitments. | EU AI Act (GPAI Code of Practice); US FTC Section 5 |
| Government / Public sector | Permits public information | Flags: Political bias, personal opinions on policy, or “hallucinating” a change in public law or eligibility. | NIST AI Risk Management Framework; EU AI Act (Prohibited Practices) |
5. Data privacy compliance rate
Definition: The accuracy rate at which agents handle PII in accordance with applicable privacy regulations and your organization’s internal data governance policies.
GDPR, HIPAA, CCPA, and a growing body of regional data privacy law create a liability exposure when AI agents mishandle personal data. Salesforce addresses this at the platform level through the Einstein Trust Layer’s zero data retention policy, and through data masking, which replaces sensitive fields with placeholder text before they reach the model. Audit trails capture interactions in event logs, providing the visibility compliance teams require.
Track the data privacy compliance rate across four dimensions:
- Whether consent signals are correctly respected before data informs personalization
- Whether data minimization principles are consistently applied
- Whether PII is properly masked in logs and agent outputs
- Whether retention rules are enforced within agent memory and contextual storage
Unlike the other metrics, there’s virtually no acceptable margin for error where regulatory compliance is at stake. Audit this metric quarterly with legal and compliance stakeholders.
As far as data privacy is concerned, it’s critical to have a verification architecture in place.
When an agent interacts with an external or unauthenticated user, there is a basic problem: the agent doesn’t know who is actually on the other side of the conversation. The appropriate response isn’t to ask users to supply sensitive identifiers. Self-reported identity isn’t trustworthy. Hence, what the agent actually needs to establish is who the user is, typically through a step-up authentication flow. This is where agent variables can come in handy.
Source: Salesforce
Salesforce’s agent variables — secure, session-scoped variables that can only be set by verified action outputs — provide a practical mechanism for this. Paired with filtering rules that gate sensitive topics behind a verified identity state, they give you a measurable, auditable chain of custody for PII handling that goes beyond passive masking.
6. Customer satisfaction delta
Definition: The difference in customer satisfaction scores between conversations handled singly by AI agents versus those handled by human agents.
This metric answers the question every marketing leader asks but often struggles to quantify: Are customers actually satisfied with AI-handled interactions?
And how does that satisfaction compare to what they’d experience with a human?
Now, a positive delta favoring human agents isn’t automatically a problem as there will always be interaction types where empathy and judgment outperform autonomous execution. What you’re monitoring is whether the gap is stable, narrowing, or widening in ways that indicate the agent is underperforming against customer expectations.
You’ll likely find that routine informational queries generate a near-zero delta, while complex complaint handling shows a larger gap favoring humans. That insight should directly inform your escalation policies and the interaction types you prioritize for agent improvement.
Tracking this metric rigorously is now more feasible thanks to Interaction Explorer, Salesforce’s observability dashboard for Agentforce deployments. It surfaces session volume, quality scores, top-ranking topics, and granular per-conversation logs, including time spent on trust-related activities, action execution, and utterance processing. This level of visibility means you can correlate specific interaction patterns or agent configurations with satisfaction outcomes.
More Agentforce governance metrics
Below are a few additional metrics you can use to tighten the scope of agentic governance.
Operational metrics
- Conversation volume (by agent, by channel)
- Resolution rate (autonomous vs. escalated)
- Average handling time
- Customer satisfaction scores
- First contact resolution rate
Quality metrics
- Hallucination detection rate
- Accuracy score trending
- Knowledge gap identification
- Edge case failure rate
Security metrics
- Permission denial logs
- Authentication failure rate
- Data access audit exceptions
- Compliance violation alerts
- Toxicity detection triggers
Business metrics
- Cost per conversation
- ROI vs. human agent cost
- Agent utilization rate
- Process automation percentage
- User adoption trending
Agentforce without governance is a liability
For all the exciting, transformative potential that Agentforce unlocks, the risks of agents misfiring are equally real. Spend a week immersed in today’s governance debates, and it can turn you into a skeptic! The consequences of agentic misadventures are very severe. AI hallucinations are particularly dangerous since “there is not yet any foolproof way of preventing LLM hallucinations,” as Oliver Patel, Head of Enterprise AI Governance at AstraZeneca, warns.
For starters, you’ll need a robust Agentforce governance framework.
That said, there will be a learning curve. There is no fully established, one-size-fits-all model of agentic governance that can be applied with complete certainty. Much of the process still involves iterating, adapting, and refining as you learn what works in your specific context.
Need help with Agentforce implementation? With over 10 years of experience in serving more than 800 SFMC clients, we can be your go-to execution partner.
Book a free, no-obligation call with one of our SFMC experts.


