

Personalization has evolved from 19th-century cobblers using manual records for custom service to modern, AI-driven, real-time 1:1 experiences. While mass production in the 20th century crippled personal touches, the rise of digital, email, and, crucially, Amazon’s recommendation engine in the late 1990s revolutionized it, shifting the focus to behavioral data. According to a McKinsey study, 71% of consumers now expect brands to provide personalized experiences, and 67% are frustrated when companies fail to tailor interactions to their specific needs.
Ah, but companies are frustrated too! The roadblocks are familiar:
- Customer data scattered across marketing, sales, and service
- Identity resolution challenges that make it impossible to recognize the same person across channels, and
- AI, with its head-turning exploits, refusing to shed the shine and become truly useful
Agentforce, Salesforce’s AI juggernaut, was built to tackle these challenges head on.
Never before have unified data, intelligent decisioning, and autonomous agents snapped together to make hyper-personalization a runtime reality, thanks to Agentforce Marketing Cloud.
Table of Contents
The architecture for hyper-personalization
1. Data Cloud: The unified foundation
2. Data graphs: Making unified data accessible
3. Salesforce Personalization: The decisioning engine
How an AI agent works in Agentforce
Why the agentic architecture is different
Where to start with Agentforce
The architecture for hyper-personalization
Salesforce has assembled a three-layer stack. Each layer has a distinct job, and together they form a closed loop from raw data to real-time customer-tailored action.
| Personalization vs. Hyper-personalization | ||
|---|---|---|
| Feature | Personalization | Hyper personalization |
| Data source | Static data (Name, location, gender, purchase history). | Dynamic data (Real-time browsing, intent, weather, GPS) |
| Timing | Reactive or scheduled | Predictive or real-time |
| Logic | Rule-based | AI-driven: Predictive modeling and machine learning |
| Goal | Customer engagement and recognition | Same, but with a more granular approach in the form of anticipatory service and friction reduction |
The first layer that powers real-time personalization in Salesforce is Data Cloud.
1. Data Cloud: The unified foundation
The entire edifice rests on Data Cloud, Salesforce’s platform for harmonizing customer data from any source into a single, unified profile.
What comes out the other side is a true customer 360: a single record capturing everything from browsing behavior and purchase history to open service cases and sales opportunities. More importantly, the profileis not a frozen snapshot; it’s continuously updated as new events arrive, enabling decisions based on what a customer did moments ago. The platform handles the heavy lifting of identity resolution and merges those disparate records into a coherent identity.
Data Cloud ingests both structured data and unstructured data and makes all of it queryable by AI agents.
A key design principle worth emphasizing: unification does not mean duplication.
Organizations can connect their existing data lakes and Data Cloud sits on top, rationalizing the data without forcing a costly migration.
The next layer for real-time personalization in Salesforce is Data Graphs.
2. Data graphs: Making unified data accessible
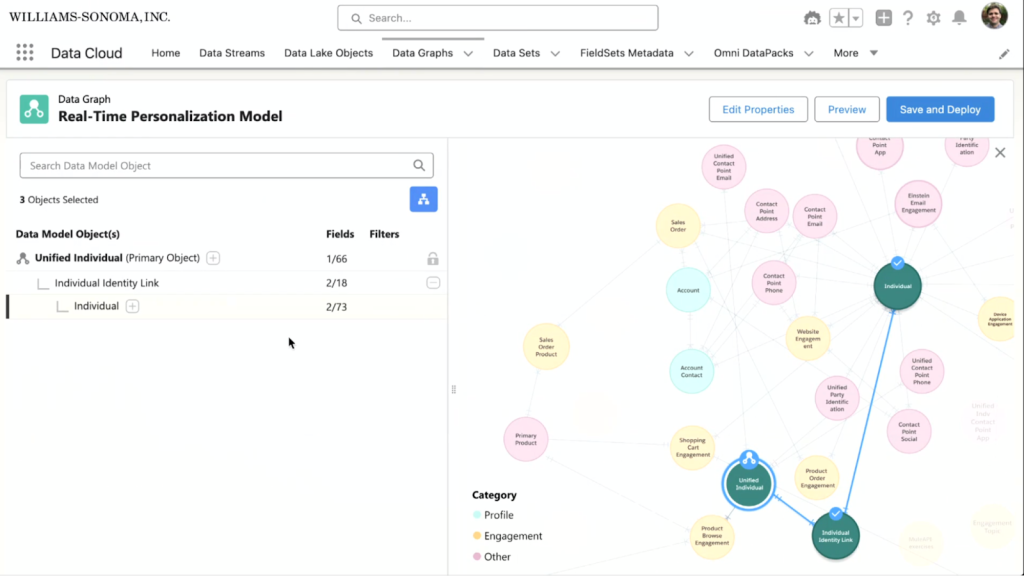
Knowing everything about a customer is only useful if that knowledge can be retrieved instantly and completely. Here’s where Data Graphs takes up the baton. A Data Graph pre-assembles all the relevant information about an individual into a JSON structure returnable in one call.
Source: Salesforce Ben
The distinction between a standard Data Graph and a real-time Data Graph is operationally significant. Real-time Data Graphs sit atop a dedicated processing layer that collapses the entire pipeline — ingestion, unification, and harmonization — to deliver sub-second profile reads.
For personalization, two Data Graphs do the heavy lifting: one representing the individual’s behavioral profile, and one representing the product catalog. Together, they give the decisioning engine everything it needs to match the right product to the right person at the right moment.
3. Salesforce Personalization: The decisioning engine
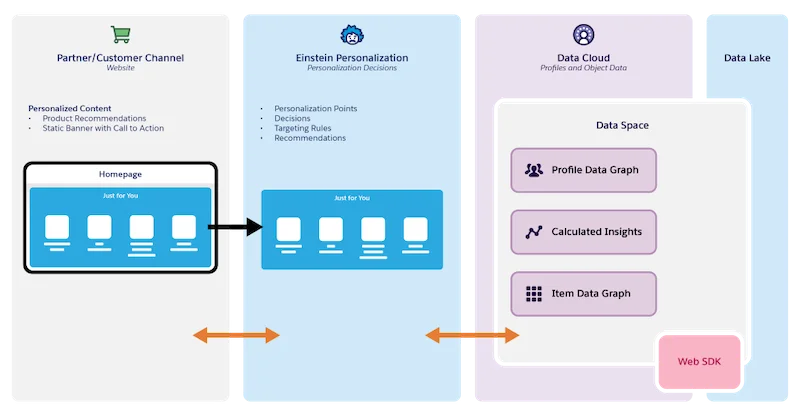
Sitting atop the data layer is Salesforce Personalization, a decisioning service that translates unified customer data into concrete recommendations.
Agentic Marketing Cloud supports two recommender types:
- Rule-based systems driven by business logic
- Objective-based recommenders that use deep learning models to optimize for a specific outcome for a specific individual
In the context of hyper-personalization, the objective-based approach is particularly powerful because it closes the feedback loop automatically. The model observes which recommendations lead to the desired outcomes, adjusts accordingly, and continuously improves.
Source: Salesforce
This is where predictive AI and generative AI begin to converge. The decisioning engine produces ranked recommendations using ML; those feed into the agent layer, which uses them as context for LLM-aligned conversation with the customer.
How an AI agent works in Agentforce
Unlike a traditional chatbot that follows a decision tree, an Agentforce agent is configured with a role, relevant data, permitted actions, explicit guardrails, and designated channels.
The integration with the personalization decisioning layer is where the science happens.
When a customer initiates a conversation, the agent pulls real-time recommendations from the decisioning engine and weaves them into the conversation naturally.
Two capabilities make this work under the hood:
- Conversational intent: What the customer or user is telling the agent feeds into the same decisioning pipeline that handles behavioral signals, so recommendations are informed by both the user’s long-term behavior and their immediate stated intent simultaneously.
- Knowledge-based questions: The agent queries the Agentforce Data Library, which then abstracts away the complexity of Retrieval-Augmented Generation, or RAG. The platform handles chunking, vectorization, and semantic indexing automatically.
Source: Salesforce
Now that may be a lot of big words. To put it simply, you break large data into manageable chunks (chunking), translate their meaning into a mathematical coordinate (vectorization), and organize them into a searchable map (semantic indexing).
At the risk of sounding absurd, it’s a bit like tearing a book into individual pages, translating each page into a GPS coordinate based on its topic, and pinning them onto a giant map so you can fly straight to the exact information you need.
The ReAct architecture in agentic marketing cloud:
Reason: The agent takes the context provided and uses its reasoning engine to select the most appropriate next action.
Act: It calls that action, passing in the necessary inputs. Salesforce executes the underlying Apex or Flow. The agent itself doesn’t run any code, it simply invokes what’s available.
Respond: The action returns a result. The agent incorporates it into its reply, then waits for the next user input, continuing the loop until the task is done.
One underappreciated data source in this loop is the call transcript history.
When an agent is asked to assess a customer or make a recommendation, it can search through prior conversation transcripts to surface context that no segment or calculated field would ever capture, such as a product mentioned in passing 3 months ago, a concern raised and never fully resolved, or a life event that signals a new financial need, and so on.
Why the agentic architecture is different
As opposed to personalization in the traditional sense, where the customer perceived as a frozen entity is the final objective, hyper-personalization doesn’t target so much the customer as the customer’s intent. That flips the axis. For it to work, one can no longer rely on static databases but need real-time streaming engines that can respond to data as it blows in. That’s why several architectural aspects differ as they must from the apparatus of traditional personalization:
- No data migration required: Data Cloud federates across existing data lakes rather than demanding a rip-and-replace.
- Real-time by design: The real-time Data Graph layer means decisions are based on what happened seconds ago.
- Predictive and generative AI play together: ML-driven recommenders handle ranking; LLMs handle conversation. Neither tries to do the other’s job.
- Built-in governance: Every LLM interaction is automatically logged, with toxicity scoring and sensitive data masking before prompts reach the model.
- No-code paths exist: Pre-built agent actions and Data Libraries mean teams can deploy personalized experiences without writing custom retrieval pipelines from scratch.
You don’t need a massive engineering team or a greenfield tech stack to get started. Teams that have spent years fixing batch jobs and building journeys are the ones doing this now.
Where to start with Agentforce
Good question. Here are a few starting principles:
- Start with the data, not agents. If your data is siloed, you are building on sand. Audit data quality across accuracy, accessibility, security, and governance.
- Pick one specific business case. For instance, order management, fraud alerts, payment reminders, and calendar reminders are high-ROI starting points.
- Convert to value from volume. A smaller number of highly relevant, well-timed messages consistently outperform broadcast approaches.
- Select your channels. WhatsApp performs best at BOFU for re-engagement, urgent alerts, and service conversations. Reserve it for high-relevance moments.
- Leverage observability from day 1. Agentforce’s built-in KPI tracking, testing center, and analytics provide the feedback loop needed to improve agents continuously.
If you need specialized guidance, we can help. With over 10 years of experience in serving more than 800 SFMC clients, we can be your go-to execution partner.


