D2C / E-commerce brand
Industry
Global D2C Retail · 4M+ customers · Multi-market
Challenge
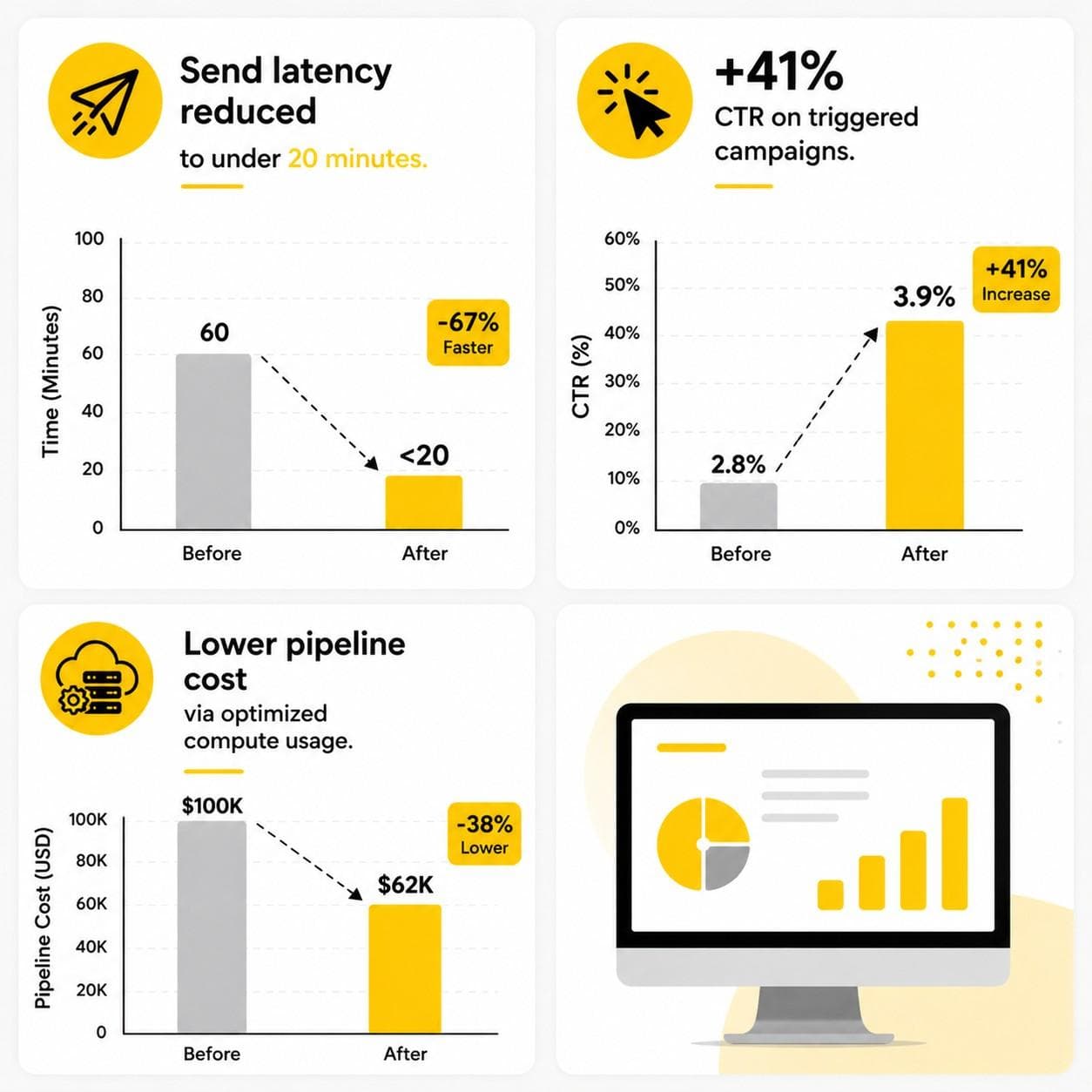
Churn model ran in ad-hoc Python notebooks with 24-hour refresh lag. Marketing relied on engineering for every audience update, slowing activation.
Solution
Mavlers moved modelling to Databricks AutoML with scheduled retraining via Workflows. Churn scores synced via Hightouch to Braze, triggering personalized winback journeys.
Outcome
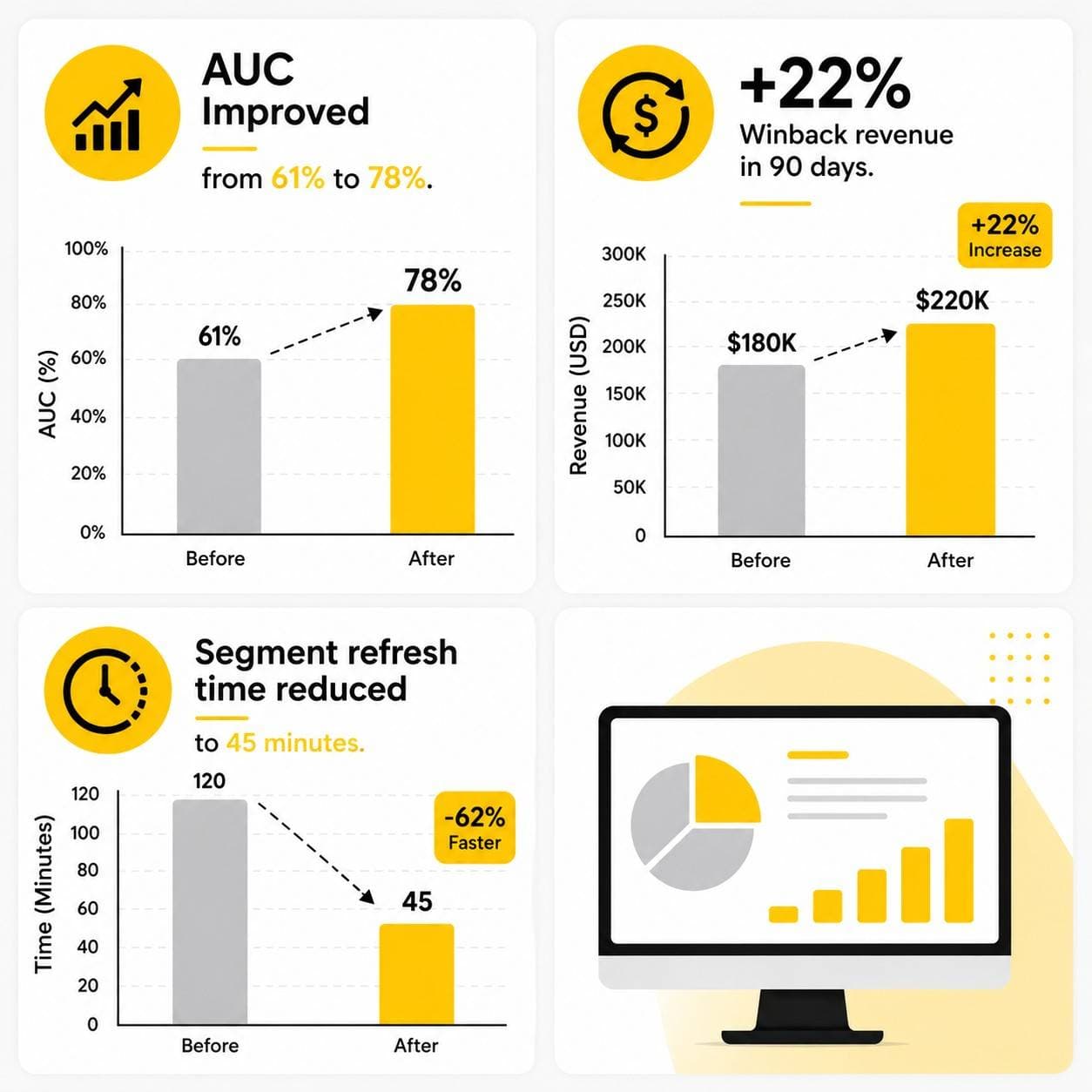
 AUC improved from 61% to 78%
AUC improved from 61% to 78%- +22% winback revenue in 90 days
- Segment refresh time reduced to 45 minutes
Stack
Databricks AutoML · Databricks Workflows · Delta Live Tables · Hightouch · Braze