

You look at a diagram of the company’s tech stack. On paper, it is beautiful. It is logical. You have the “Best of Breed” CRM, the enterprise-grade Marketing Automation Platform, the modern Customer Data Platform (CDP), and the cloud Data Warehouse.
It is a familiar scene in almost every enterprise architecture review.
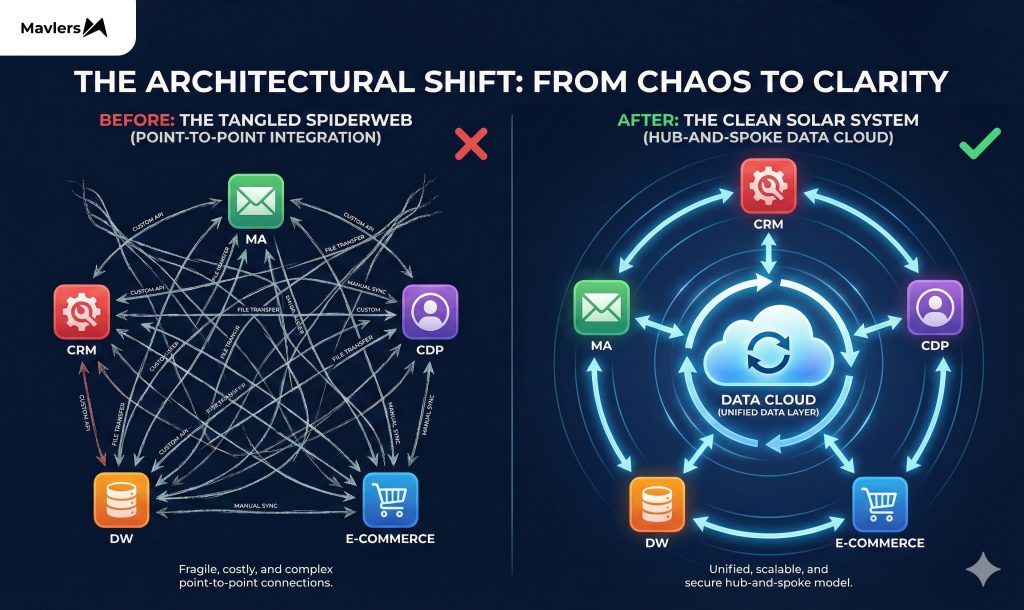
Connecting them all is a spiderweb of lines representing APIs, ETL jobs, and reverse-ETL syncs. Technically, the data is flowing. But ask the operational teams running this machine, and you get a different story.
They will tell you that the data flows, but it never quite arrives on time. It rarely arrives in sync. And frequently, it doesn’t arrive intact.
We have reached an inflection point. The next phase of stack evolution isn’t more integration, it is de-integration.
Let’s cut to the chase and figure out the de-integration change that will simplify your tech stacks.
How we got here: The rise of the integration-first stack
To understand why we are de-integrating, we have to understand how we built this complexity in the first place.
Firstly, what was the original promise of middleware
In the early days of the cloud transition, middleware was the hero. It promised to abstract away the complexity of point-to-point connections. Instead of writing custom code to make System A talk to System B, you used a middleware platform to handle the translation.
This promised three things:
- Abstraction: You didn’t need to know the underlying API logic of every tool.
- Best-of-breed connectivity: You could buy the best tool for every specific job and trust that they would work together.
- Flexibility: You could swap out your Support platform without breaking your Sales platform.
Why middleware became the default
The explosion of SaaS made middleware mandatory. As companies moved from on-premise suites to cloud point solutions, the data became fragmented. Fears of vendor lock-in drove CIOs to buy disparate systems, creating a massive need for a shared data layer.
The typical enterprise reality today
Today, a standard mid-to-large enterprise stack looks like a patchwork quilt:
- CRM (Salesforce, HubSpot)
- Marketing Automation (Marketo, Braze)
- Data Warehouse (Snowflake, BigQuery)
- Analytics (Tableau, Looker)
- Support (Zendesk, Intercom)
Each of these is “integrated” via a complex combination of ETL tools (like Fivetran), iPaaS platforms (like MuleSoft or Workato), and custom-coded API scripts running on a cron job somewhere in the cloud.
Now, let’s discuss what happens when you end up with more integrations than required.
Why the “more integration” strategy no longer scales
We have reached a breaking point where adding more connection tools is fueling the fire rather than putting it out.

Here are three reasons why over-integration no longer helps in scaling.
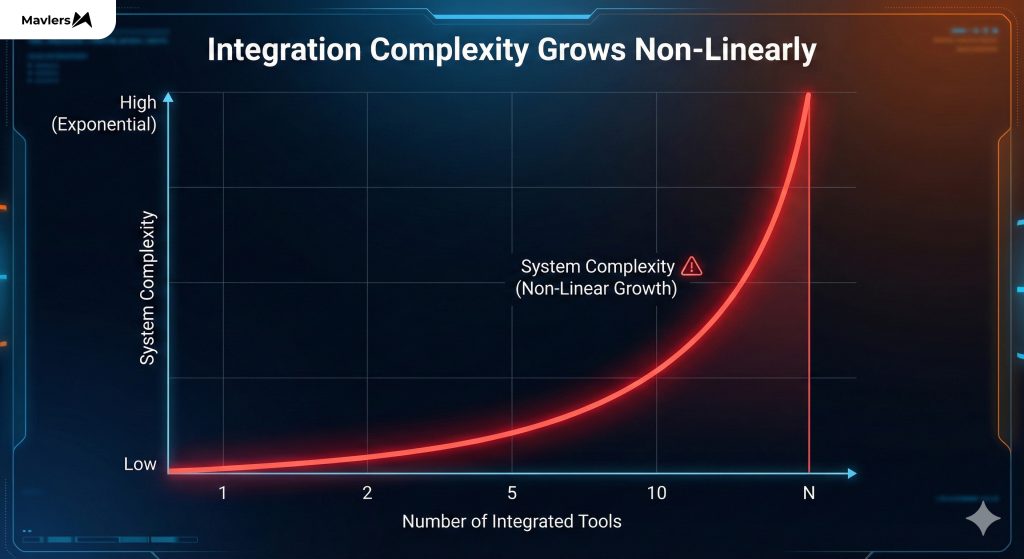
- Integration complexity grows non-linearly
Complexity in a distributed system does not grow linearly; it grows exponentially. Every new tool you add to the stack increases the number of connection points, failure surfaces, and the monitoring burden.
- Observability breaks down
In a hyper-integrated stack, observability becomes a nightmare. If a customer’s address is wrong in the shipping software, where did the error originate?
- Did the customer enter it wrong?
- Did the CRM truncate the field?
- Did the ETL job map it incorrectly?
- Did the reverse-ETL tool overwrite it with old data?
Tracing the “source of truth” becomes impossible when data is constantly in motion between systems.
- Security and compliance risks increase.
From a security perspective, movement is risky. Every time you move data from System A to System B, you are creating a copy.
You are duplicating Personally Identifiable Information (PII) across multiple databases. This creates more attack surfaces for hackers and makes access control enforcement (like GDPR/CCPA requests) incredibly difficult.
If a user asks to be deleted, you have to hunt their data down across 15 different systems.
That brings us to the point where we need to find a way to resolve the complex data-hunting norms.
Introducing the de-integration trend
The industry’s answer to this untenable complexity is de-integration.
What de-integration actually means
De-integration is not about having fewer capabilities. It is about having fewer copies.
- Fewer data copies.
- Fewer sync jobs.
- Fewer intermediary layers.
- More direct, native access.
What it does NOT mean
It does not mean ripping out your CRM or abandoning best-of-breed specialization. It does not mean returning to a monolithic “all-in-one” platform from the 1990s.
The core principle of de-integration is simple: Move the logic to the data, not the data to the logic. Instead of copying data into an application so the application can use it, the application should reach out and read the data where it already lives.
The rise of the data cloud as a shared system of truth
This architectural shift is made possible by the evolution of the Data Warehouse into the Data Cloud.
Why data warehouses evolved into data clouds
Legacy data warehouses were storage lockers. You put data in for reporting. Modern Data Clouds (like Snowflake, Databricks, and Google BigQuery) are different. They utilize a separation of compute and storage. This allows for elastic scaling and fine-grained access control.
Snowflake as a canonical example
Snowflake (and its peers) enables a centralized, governed data layer. It supports secure data sharing across domains without copying files.
Why the data cloud changes integration math
Because the Data Cloud can handle massive concurrency (many users reading data at once), it changes the math of integration. You no longer need to extract data to use it. You can have one authoritative copy of the data and allow multiple consumers (apps) to read from it.
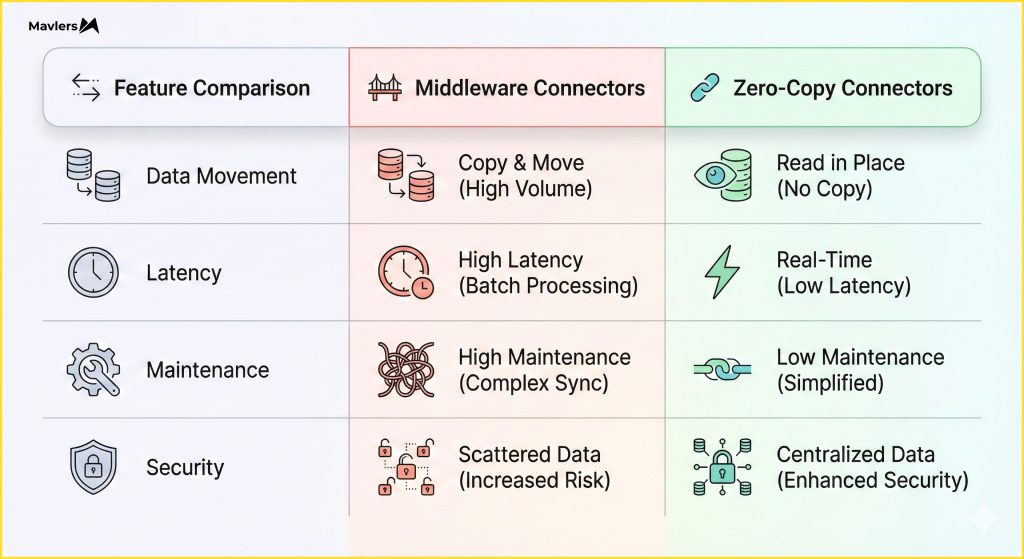
What are native, zero-copy connectors?
The mechanism that enables de-integration is the Zero-Copy Connector.
A zero-copy connector is a direct connection between a SaaS platform and a Data Cloud that allows the SaaS platform to query or reference shared data without extracting and reloading it. It preserves a single source of truth.
How zero-copy works conceptually
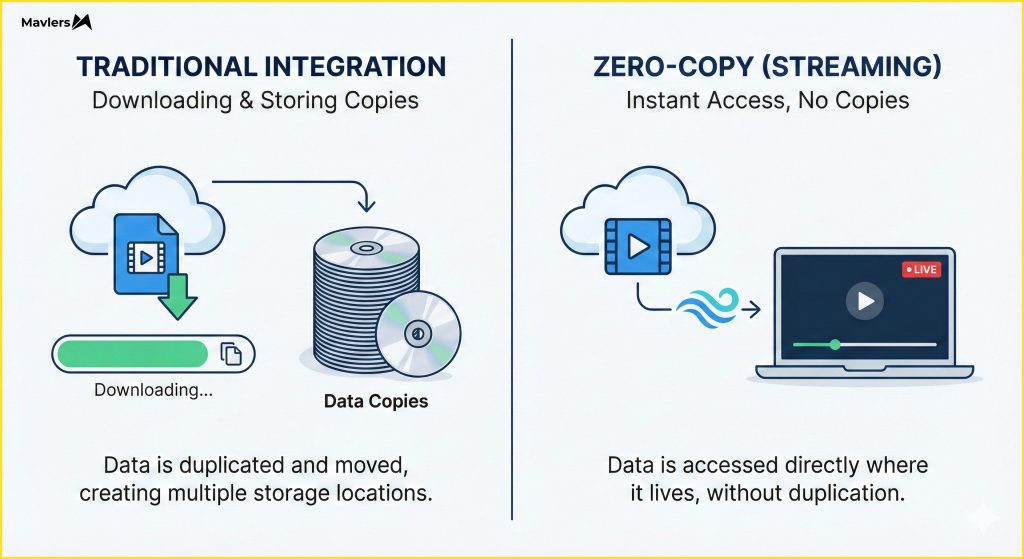
Imagine streaming a movie on Netflix versus downloading a movie to a DVD.
- Traditional Integration (Downloading): You copy the file. You own the copy. If the studio updates the movie, you have the old version.
- Zero-Copy (Streaming): You view the source. You don’t hold the file. If the source updates, you see the update instantly.
In a zero-copy architecture, the data remains in the Data Cloud. The downstream platform accesses it securely via a “share” or a direct query. No physical replication is required.
Here are some examples:
- Snowflake → Salesforce Data Cloud: Salesforce can “mount” Snowflake tables and treat them as if they were native Salesforce objects, without moving the data.
- Snowflake → Braze: Braze Cloud Data Ingestion allows Braze to grab audience data directly from the warehouse the moment it is needed for a campaign.
| Dimension | Middleware-Based Architecture | Native Zero-Copy Architecture |
| Architecture | Extract → Transform → Load → Sync → Monitor. A linear pipeline full of friction. | Govern → Grant → Query → Activate. A permission-based access model. |
| Latency | Batch or near-real-time (minutes to hours). | Real-time or near-instant (seconds). |
| Reliability | Sync jobs can fail, stall, or time out. | Direct access via the Data Cloud (≈99.99% uptime). No “sync failure” concept. |
| Operational Complexity | Custom mappings, API limits, retries, and error logs to manage. | Native schemas and SQL views. Fewer moving parts. |
| Feature | Middleware Integration | Native Zero-Copy Connector |
| Data Movement | Copies data between systems | Reads data in place |
| Latency | Batch / Periodic | Real-time / On-demand |
| Maintenance | High (API updates, broken syncs) | Low (Schema management) |
| Security | Data sprawled across systems | Data is centralized and governed |
| Cost | License + Usage + Ops Labor | Compute + Storage |
Total cost of ownership (TCO): The real business use case
For executives and architects, the argument for de-integration is ultimately financial.
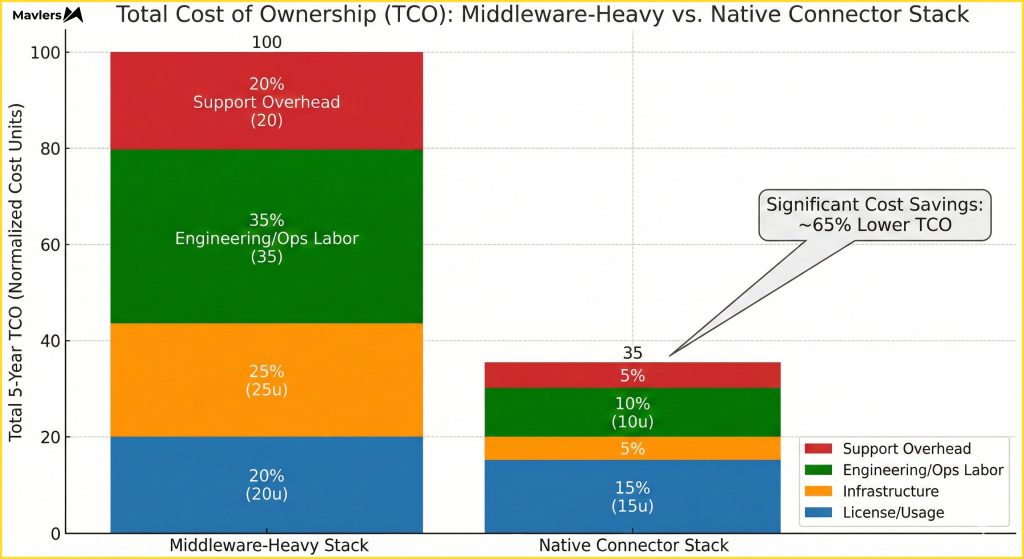
- Cost categories to evaluate
When modeling TCO, you must look beyond the license. You must evaluate infrastructure, engineering time, support overhead, and the cost of downtime/errors.
- TCO modeling: Middleware-heavy stack
In a traditional stack, you are paying multiple vendors. You are paying usage-based fees for data volume. And most expensively, you are paying for dedicated operations resources to manage the pipelines.
- TCO modeling: Native connector stack
In a de-integrated stack, you have fewer vendors. You have drastically lower operational overhead because there are no pipelines to break. You reduce data duplication costs (storage fees).
- Long-term compounding benefits
The benefits compound over time. As your data volume grows, the marginal cost of a zero-copy architecture is lower than that of a movement-based architecture. Furthermore, when you inevitably re-platform or scale, there is less “glue code” to rip out and rewrite.
Latency, accuracy, and trust: Why zero-copy changes decision-making
Beyond cost, de-integration improves the quality of the business.
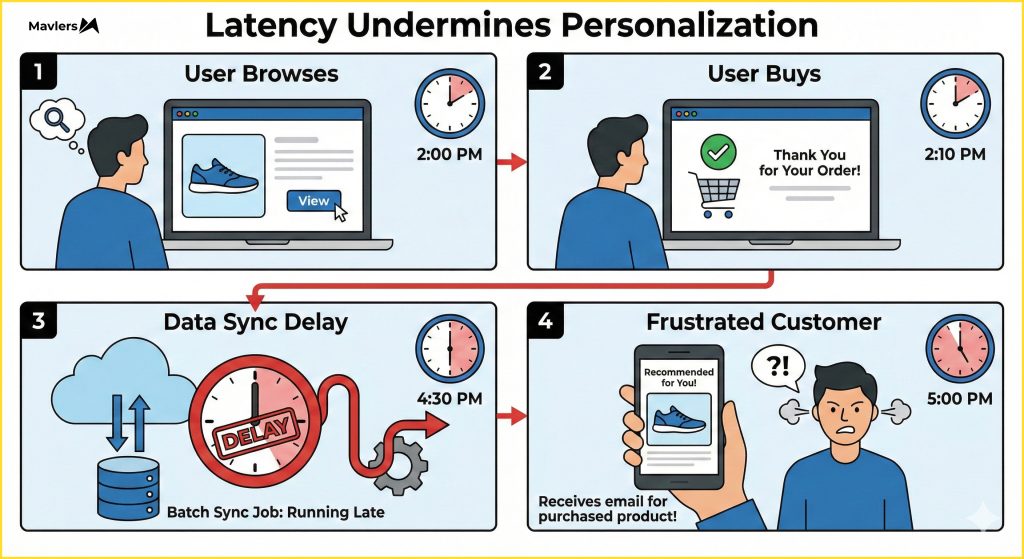
Why latency undermines personalization
Customer behavior changes faster than batch syncs.
If a user browses a product, buys it, and then receives an email recommending that same product 30 minutes later because the “Purchase” data hadn’t synced to the marketing tool yet, the customer experience is broken.
Zero-copy solves this by checking the source of truth at the moment of send.
Why sync errors destroy confidence
When dashboards in Salesforce don’t match dashboards in Tableau, teams stop trusting the data. They revert to manual spreadsheets and overrides.
Real-time access restores trust.
When everyone is looking at the same data, not a copy of a copy, trust is restored. Decisions are based on the current state. Marketing, sales, and CX are aligned because they are reading from the same book.
Real-life use cases where de-integration shines
Here are some examples of how to make the best use of de-integration.
- Real-time customer engagement
De-integration allows for true behavioral triggers. You can achieve in-session personalization where the website adapts based on the user’s lifetime value (LTV) stored in the warehouse, instantly.
- Cross-platform identity resolution
It reduces the issue of mismatched profiles. Because the Data Cloud handles identity resolution, downstream tools just read the resolved profile.
- Marketing activation without data movement
Audiences can be built once in the Data Cloud using complex SQL logic, and then “activated” everywhere without having to rebuild the segment logic in every tool.
- Analytics without reconciliation
You have one dataset. You have multiple perspectives (BI tool, CRM, etc.), but they all point to the same numbers.
What this means for Salesforce, Braze, and modern stacks
The major platforms are betting their future on this trend.
Salesforce Data Cloud as an access layer
Salesforce is aggressively moving toward this model with Data Cloud (formerly Genie). It acts as an access layer that can virtualize data from Snowflake, Google BigQuery, and AWS Redshift. It allows Salesforce users to see and use petabytes of data without importing it into Salesforce rows.
Braze as a real-time consumer of cloud data
Braze’s Cloud Data Ingestion is a prime example. Instead of syncing user attributes into Braze, Braze simply reaches out to the warehouse to fetch the data needed to personalize a message right before it sends.
We are moving from a world where systems “sync” to a world where systems “subscribe” to governed data views.
Now, let’s discuss how governments and security systems protect de-integration.
Governance and security advantages in de-integration
For the Chief Information Security Officer (CISO), de-integration is a dream. Here are some security advantages you get in de-integration.
- Centralized access control
You have one place to manage permissions. If you revoke access in the Data Cloud, the downstream tool instantly loses visibility.
- Reduced data sprawl
Fewer copies means lower risk. You don’t have PII sitting in forgotten S3 buckets or staging tables.
- Audibility and compliance
Lineage is clear. You know exactly who accessed the data and when. Audits become significantly easier because the data trail is contained within the Data Cloud logs.
But the grass won’t always be greener on the other side. You are bound to face some challenges along the way.
Let’s take a look at what those challenges are and how you can tackle them.
Common objections, and why they’re fading
Here are some common misconceptions about de-integration you need to be aware of, although they are already less prevalent than before.
- “Middleware gives us flexibility.”
The argument is that middleware decouples systems. But in reality, fragility often disguises itself as flexibility. Direct, governed sharing is actually more flexible because changing the data schema in the warehouse propagates instantly.
- “We’ve already invested heavily.”
The Sunk Cost fallacy is strong. Companies hesitate to abandon their expensive MuleSoft implementation. But the future cost of maintaining that legacy architecture is higher than the cost of switching.
- “Native connectors are vendor lock-in.”
Some argue that relying on Snowflake or Salesforce creates lock-in. While true, “data gravity” means you are likely locked into your storage layer anyway. The operational drag of middleware is a worse form of lock-in than choosing a storage vendor.
When de-integration is not the right move
De-integration is not a magic bullet for everything. Here are a few instances when you should refrain from de-integration.
- For highly bespoke transformations: If you need to transform data in highly complex ways that the native connector doesn’t support, you may still need an ETL layer (like dbt) before the data is ready to be shared.
- For legacy systems without native support: There are thousands of legacy on-premise apps that simply cannot do zero-copy sharing. They still need old-school integration.
- For transitional architectures: Sometimes you need a hybrid approach during migration.
- For regulatory constraints, in some specific jurisdictional cases, data movement rules might actually require physical separation, though this is rare.
Need some more advanced implementation tips? We have got your back.
5-Step practical roadmap to de-integration
How do you eat this elephant? One bite at a time.
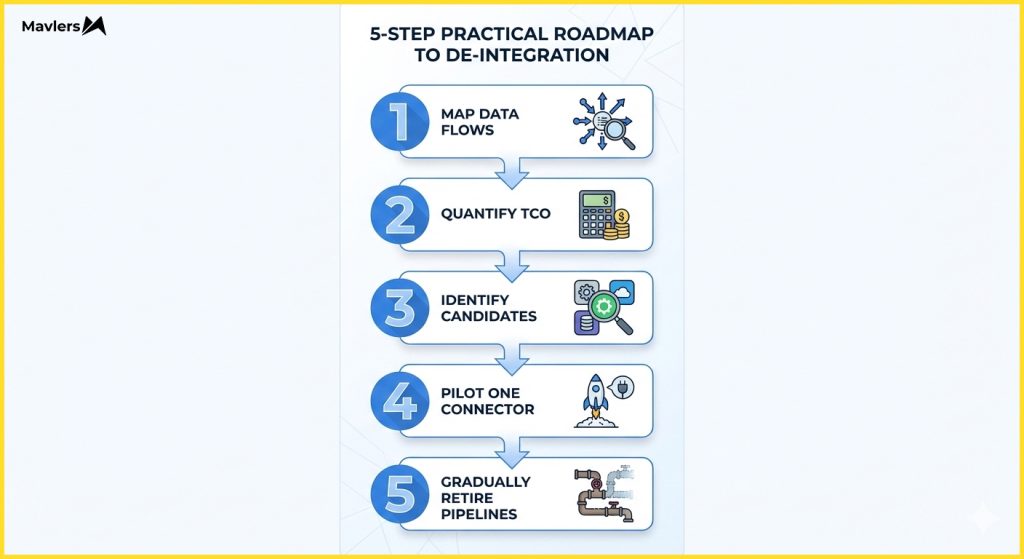
Step 1: Map your data flows
Identify where duplication is happening. Find the points of highest latency.
Step 2: Quantify middleware TCO
Look at your bills. Look at your incident tickets. Calculate how much your current “glue” is costing you.
Step 3: Identify zero-copy candidates
Look for high-volume, high-frequency, or high-risk syncs. These are your best targets.
Step 4: Pilot with one native connector
Don’t rip everything out. Pick one connection, say, Snowflake to Braze. Measure the latency improvement. Measure the reduction in ops effort.
Step 5: Gradually retire redundant pipelines
Once the pilot proves successful, you can decommission the old ETL jobs with confidence.
Any guesses on how the future is lined up for this? Let’s find out.
What the de-integration trend signals for the future
While the future is vast and full of surprises, here are three forecasts that point to de-integration.
Stacks will get smaller, but smarter
We are heading toward a future where the tech stack diagram is cleaner. It will look less like a spiderweb and more like a solar system, with the Data Cloud as the sun and apps orbiting it.
Architecture will prioritize:
- Fewer layers.
- Clear ownership.
- Direct access.
Integration won’t disappear, but it will become the exception, not the rule.
We will still need integration for edge cases, but it will no longer be the default way we build systems.
Wrapping up
That brings us to the business end of this article, where it’s fair to say that the cleanest stack is the one you don’t have to babysit.
We have spent the last decade building stacks that require an army to maintain.
We built pipelines that leak, connectors that break, and maps that don’t match the territory.
The de-integration trend offers a way out. It is a return to simplicity.
Every extra integration layer is a tax. Native connectors are how modern stacks stop paying it.
The cleanest stack is the one where the data simply is, rather than one where the data is constantly moving.
It’s time to create an actionable strategy based on the learnings from this article that will help you generate actual results.
The ball is in your yard now.
Here are some more relatable topics you would like to take a look at.
Lifecycle marketing in 2026: How to solve data integration problems
From data silos to seamless personalization in retail: The power of zero-copy integration in Braze
Unlocking marketing agility: Why you need a composable martech stack & how to build one


