There comes a moment in every successful e-commerce business’s journey when competition stops feeling reactive and instead starts feeling prescient.
You change the price of a service, and suddenly a competitor mirrors it almost immediately.
One of your products is running a little low on stock, and suddenly, your competitor runs ads pushing an alternative.
On similar terms, a bestseller quietly carries the business for weeks, and then a near-identical SKU shows up elsewhere.
Nothing overt and nothing illegal.
Just an unsettling sense that your storefront is no longer just being visited, it’s being observed.
At scale, this is no longer anecdotal. It’s structural.
Modern AI-driven e-commerce bots continuously scrape pricing, availability, bestseller ordering, and promotional timing.
Not to copy you wholesale but to remove uncertainty from their own decisions.
And that’s where the real cost begins.
When pricing stops being a strategy
So, most founders don’t lose sleep over competitors seeing their prices because transparency is a part of commerce.
However, what truly becomes exhausting is when competitor price scraping turns pricing into a reactive loop.
You test, they watch.
You learn, they respond, albeit without paying the learning cost.
As time progresses, your storefront becomes less a sales channel and more a training dataset for someone else’s automation.
Inventory behaves the same way. Stock levels, bestseller rankings, and urgency messaging leak information about velocity, demand, and timing.
To a human shopper, these are cues; however, to a bot, they’re clean, structured, and incredibly valuable signals.
This is why founders eventually stop asking “How do we block bots?” and start asking a quieter, more uncomfortable question, “Why are we still telling them the truth?”
Why blocking feels right and fails quietly
While the instinct to block is understandable, it’s also rooted in an older internet.
Modern automated scraping doesn’t rely on obvious crawlers or static IPs. Instead, it rotates identities, executes JavaScript, mimics human behavior, and adapts when challenged.
Blocking creates friction, but often for the wrong audience.
Legitimate crawlers get caught in the net, UX degrades under CAPTCHAs and false positives, SEO and performance take subtle hits.
And the scrapers, well, they simply come back differently.
More importantly, blocking sends a signal that you’ve been noticed.
The most effective stores don’t escalate, instead they become unreadable.
| What blocking does | Who it hurts |
| CAPTCHAs & rate limits | Real users |
| False positives | SEO crawlers |
| UX friction | Conversion rates |
| Public confrontation | Signals competitors |
The shift that changes everything, choosing control over confrontation
The stores that actually stop competitor price scraping don’t fight bots head-on, instead they do something calmer.
They accept that scraping will happen and remove its value.
This requires a mindset shift; pricing, inventory, and bestseller data may be visible to customers, but they don’t need to be consistently precise for every automated observer.
And once you internalize that, the tactics become almost obvious.
The goal is to detect intent instead of identity
According to the 2024 Imperva Bad Bot Report, nearly 49.6 % of all internet traffic came from bots. So, the goal isn’t to identify who the bot belongs to, because honestly, that’s a dead end.
What matters is understanding why a session exists.
Also, competitor scraping sessions behave differently from shoppers. In the sense that they are known to;
~ Traverse SKUs methodically
~ Care deeply about price and product availability
~ Rarely convert
~ Repeat patterns with unnatural consistency
So, modern bot detection systems don’t look for certainty. They look for confidence.
Once a session exceeds the e-commerce scraping confidence threshold, it doesn’t need to be blocked. It simply needs to stop seeing clean data.
How stores quietly break price scraping (without breaking pricing)
So, price scraping only works when pricing behaves like a spreadsheet, in a stable, exact, and predictable way.
Interestingly, that’s what makes it valuable to competitors.
Now, bots don’t understand pricing; they compare deltas by looking for patterns, thresholds, and triggers. When prices move cleanly and predictably, automation thrives.
So, the goal isn’t to hide prices; it is to stop making them machine-perfect!
We need to tweak them just enough to introduce an element of uncertainty.
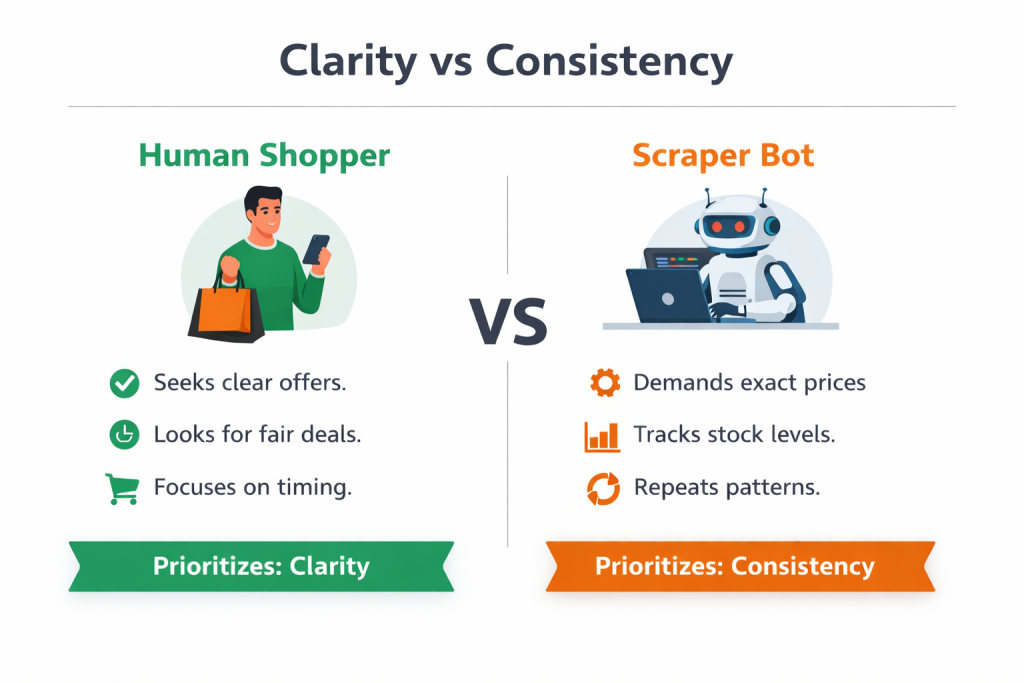
Getting clarity on the principle ~ where customers need clarity and bots need consistency
Now this distinction truly matters because real shoppers don’t care if a price is $199 or $198.73.
Instead, they care about whether the deal that they are being offered is fair, competitive, and whether it is the right time to buy.
Scrapers, on the other hand, care deeply about exactness. Their entire value comes from comparing your price against hundreds of others with mathematical precision.
So stores that want to slow competitor price scraping focus on where precision matters and where it doesn’t.
Subtle price offsets (understanding why pennies matter more than dollars)
One of the simplest and most effective techniques is to introduce micro-variation in the prices served to high-confidence scraper sessions.
This doesn’t mean fake prices or dramatic swings.
Instead, it means introducing minor cent-level offsets, slight rounding differences, and non-deterministic pricing outputs.
For instance, $199.00 becomes $198.91, and $49.99 occasionally resolves as $50.02.
Now, to a human, this minor change might be invisible, however for a scraper trying to build a clean comparison table, this can be quite disconcerting.
Because once prices stop lining up perfectly across repeated scrapes, confidence collapses. And when confidence collapses, automation loses its advantage.
Breaking “repeatability” without breaking trust
Scrapers depend on repeatability more than accuracy.
If a bot scrapes your product page five times and gets five identical prices, it assumes the data is reliable, that changes are meaningful, and that reactions should be immediate.
But if the same bot sees small, unexplained variance, it can no longer tell if it’s a pricing test, a geo-based adjustment, a timing issue, or a rendering quirk.
While humans rarely notice this ambiguity, algorithms despise it.
And that, ladies & gentlemen, is the quiet win we seek!
Delayed resolution of promotional pricing
Promotions are especially valuable to competitors because they reveal details like discount depth tolerance, promotion cadence, and reaction windows.
So some stores avoid immediately applying promotional prices to sessions flagged as potential scrapers.
What that looks like in practice is that list prices render first, promotional logic resolves later, and discounts require additional interaction or time.
Customers experience this naturally as pages load progressively all the time.
On the other hand, bots scraping HTML snapshots often capture incomplete pricing, pre-discount values, and inconsistent promo application.
Again, nothing is “wrong”; it’s just not reliably extractable.
An insight into why this works better than blocking
Honestly, the key advantage here is psychological and not necessarily technical.
Blocking tells a competitor, “We see you.”
While subtle mispricing tells them nothing at all.
From their perspective, the data feels inconsistent, scrapes don’t line up cleanly, and signals conflict over time.
And once a competitor stops trusting your pricing data, they stop reacting to it automatically.
That’s when you regain breathing room.
On that note, it’s worth saying this clearly.
You’re not misleading customers, altering checkout prices, or manipulating transactions.
You’re protecting pricing signals, not prices themselves.
Every real buyer still sees a clear price, a fair offer, and a consistent checkout experience.
Only automated observers lose clarity, and that’s intentional.
Make scraping expensive, not impossible
The most effective website scraping prevention doesn’t announce itself.
Instead, it rate-limits price-heavy behavior, increases computational cost for bot-like traversal, and requires more effort to extract structured data.
Humans browse inefficiently by nature, while bots optimize relentlessly.
By raising the cost of extraction without blocking access, scraping becomes a poor return on investment, and eventually, it moves elsewhere.
Stating the non-negotiables ~ never punish real customers!
This entire strategy only works if it remains invisible to buyers.
So no CAPTCHAs, login walls, broken SEO, or degraded checkout flows.
If a customer ever feels friction, the system is wrong.
The best implementations are mundane from the outside and frustrating only to machines.
What success actually looks like
The true measure of success is not when the bots start disappearing, but when competitors slow down.
When their prices lag, their inventory bets miss, and their reactions feel hesitant again.
Eventually, someone on their side says the sentence you’re aiming for, “We can’t rely on their data.”
That’s the win.
Not confrontation or secrecy, just well-planned, strategic opacity.
The road ahead
In case you want to know how to effectively leverage AI for your Shopify store, you might want to read this next ~ AI for Shopify stores: Practical ways to automate, personalize, and grow your business.